The NWB Software
Ecosystem
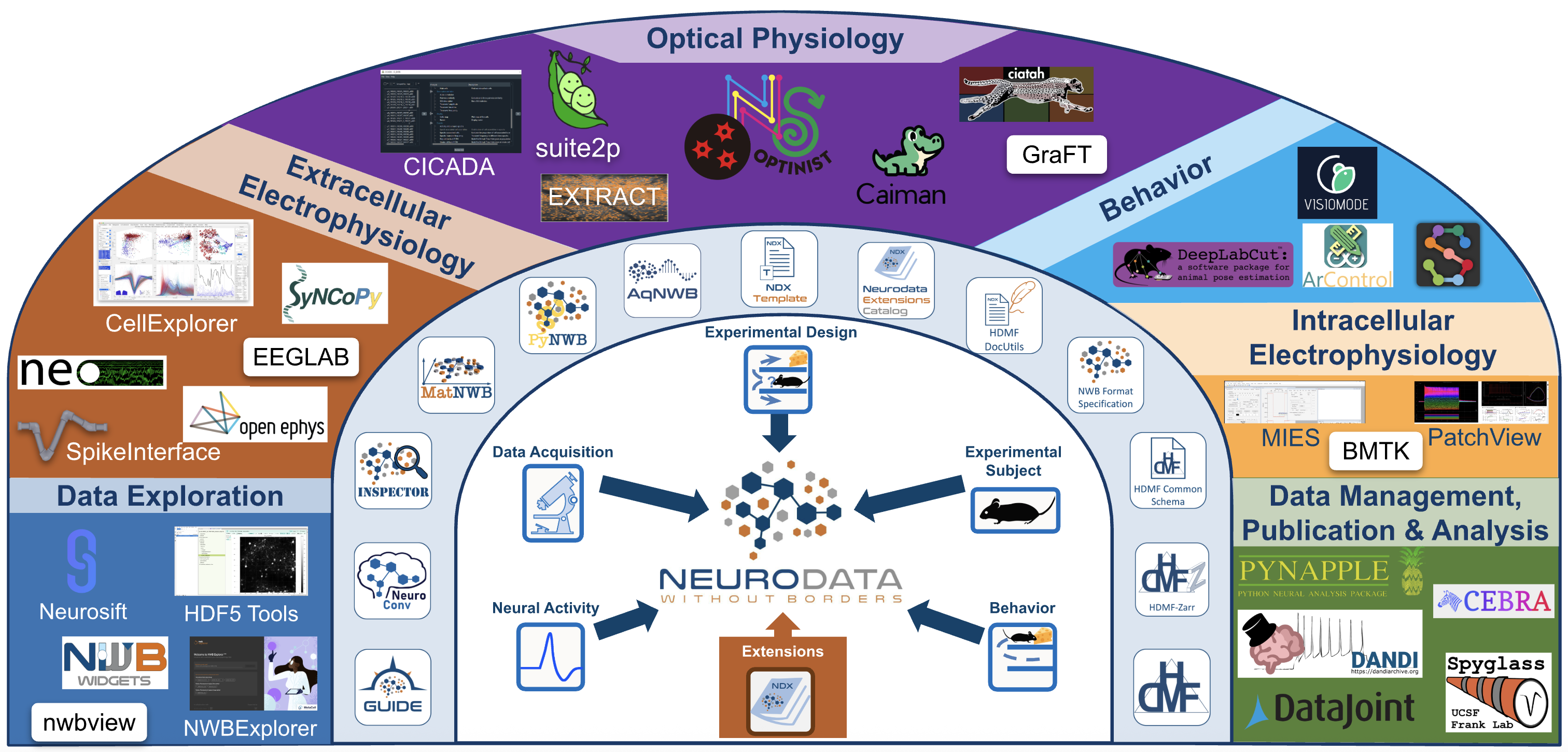
Areas of Concern and Types of Software in the NWB Ecosystem
NWB is more than just a file format; it defines an ecosystem of tools, methods, and standards for storing, sharing, and analyzing complex neurophysiology data. The following provides a high-level overview of the main components for the NWB data standardization ecosystem. For each component we provide an overview of the problem, its function, and a description.

Specification Language
How to formally define neuroscience data standards?

Data API(s)
How to efficiently interact with (read, write, query, analyze…) neuroscience data?

Data Storage
How to store large collections of neuroscience data?

Data Standard Schema
How to organize complex collections of neuroscience data?

Specification Language
Definition of neuroscience data standards.
To support the formal and verifiable specification of neurodata file formats,
NWB relies on the NWB specification language.
The specification language provides mechanism to formally specify the
organization of data.
The specification language is defined in YAML (or JSON). The specification language defines formal structures for describing the organization of complex data using basic concepts, e.g., Groups, Datasets, Attributes, and Links. The specification language is used to extend the format, which is necessary to store types of data that are not currently managed by the format
Specification Language Documentation

Data API(s)
Efficient interaction with neuroscience data.
Develop APIs that provide easy-to-use representations of NWB neurodata types for programmatic use and enable the mapping of these representations to/from data storage based on the NWB format specification.
The role of data API(s) is to facilitate efficient interaction with neuroscience data stored in the NWB data format (e.g,. for reading, writing, querying, and analyzing neuroscience data). An API provides a stable and usable interface for programmatic use and development of new applications. The API should insulate developers and users from implementation details related to the specification language, format specification, and data storage.
NWB currently provides the following APIs
PyNWB
Python reference API for NWB 2 to read, write, use, extend, and analyze data stored in NWB. Documentation Source (GitHub)
MatNWB
Matlab API for NWB. Documentation & Source (GitHub)
In addition to the core APIs developed by the NWB team, there is a growing collection of software tools and libraries that support NWB. See our Community Tools page for a list of tools that support NWB.

Data Storage
Storage of large collections of neuroscience data.
The NWB format currently uses the Hierarchical Data Format (HDF5) as primary storage mechanism.
Data storage maps NWB primitives (Groups, Datasets, Attributes, Links etc.) to storage. In the case of HDF5 this is currently mostly a 1-to-1 mapping as the NWB primitives largely match HDF5 primitives.
HDF5 was selected for the NWB format because it meets several key requirements. First, HDF5 it is a mature data format standard with libraries available in multiple programming languages. Second, HDF5’s hierarchical structure allows data to be grouped into logical self-documenting sections. The HDF5 structure is analogous to a file system in which its “groups” and “datasets” correspond to directories and files. Groups and datasets can have attributes that provide additional details, such as authorities’ identifiers. Third, the HDF5 linking feature enables data stored in one location to be transparently accessed from multiple locations in the hierarchy. The linked data can be external to the file. Fourth, HDF5 is widely supported across programming languages (e.g., C, C++, Python, MATLAB, R among others) and tools, such as, HDFView, a free, cross-platform application, can be used to open a file and browse data. Fifth, the HDF Group, a nonprofit group, ensures the ongoing accessibility of HDF-stored data.
Data Storage Documentation

Data Standard Schema
Organization of complex collections of neuroscience data.
Organize data hierarchically using easy-to-use primitives, e.g., Groups (similar to Folders), Datasets (n-D Arrays), Attributes (Metadata objects on Groups and Datasets), and Links (links to Groups and Datasets).
The format specification formally specifies the organization of neuroscience data. The format specification provides a verifiable, computer and human readable document that governs the NWB format. The format specification is, hence, central to support development of API’s and codes compliant with the NWB format and extension of the NWB format.
he NWB format standard is governed by a formal format specification, the NWB schema that is formally specified using the NWB specification language. A new schema file will be published for each revision of the NWB format standard. Developers can use the schema to validate NWB files or create advanced APIs for NWB data.
Data Standard Schema Documentation
Sources (GitHub)
Community Tools
Listed below are tools for working with NWB data. This is not a comprehensive list of NWB tools. Many of these tools are built and supported by other groups, and are in active development.