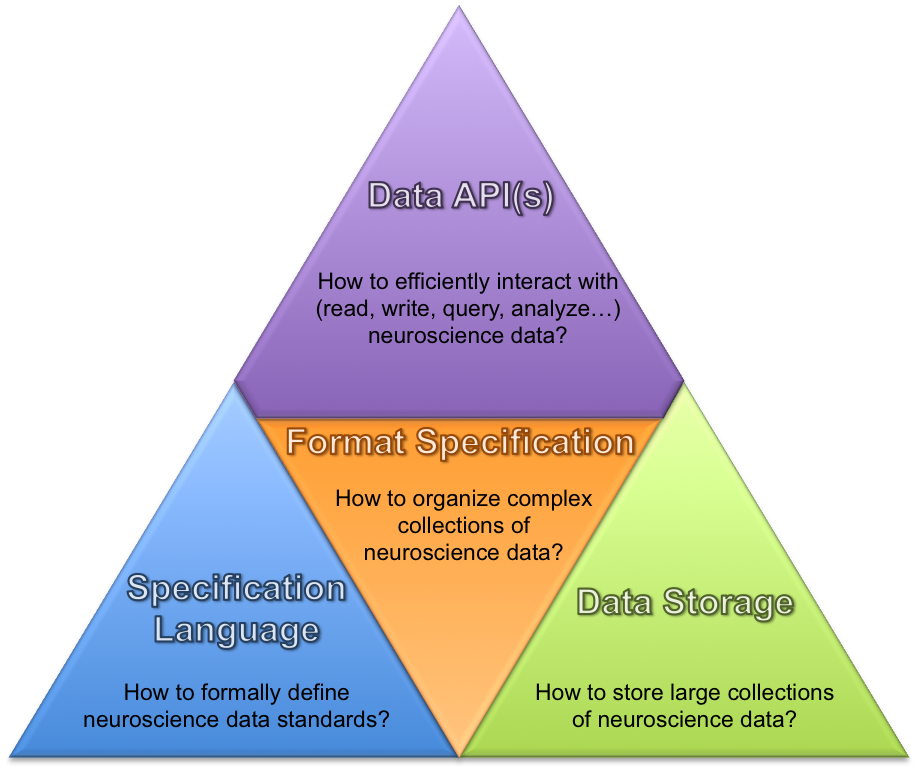
New modular software architecture and APIs to enable users/developers to efficiently interact with the…
Unlocking the Brain With Open Data
Data sharing on a massive scale transformed the field of astronomy. Is neuroscience next?

IF HISTORY IS A LESSON, neuroscience is due for a disruption.
Open data—information that is free to access, use and share—has transformed the fields of astronomy, particle physics and genetics. In astronomy, change came in the form of the Sloan Digital Sky Survey (SDSS), currently the world’s largest survey of the Universe. When it launched 16 years ago, its leaders made the data freely available for the world to use. They also built software tools to help scientists access and analyze those data. In the process, they changed how astronomers study the Universe: Researchers now mine massive data sets generated by others to gain a better understanding of cosmic phenomena.
Advocates say the same transformative step is now needed to reveal the secrets of the brain. While today’s neuroscientists are generating data at unprecedented rates, much of it is proprietary, siloed in laboratories and gathered in formats that are incompatible. This is why research leaders such as the Allen Institute for Brain Science are trying to break this century-old tradition by promoting open science. It is also why global leaders, who met at the United Nations General Assembly in September, are establishing an International Brain Station—a community-driven platform to facilitate data sharing and analysis among neuroscientists worldwide.
In this roundtable discussion, The Kavli Foundation spoke to one of the founders of the Sloan Digital Sky Survey and two neuroscientists who are working to make data sharing the new norm. We asked them what neuroscience has to gain from open data and whether the tools astronomers developed to map the sky can also help neuroscientists study the brain.
The participants were:
- CHRISTOF KOCH, PhD – is President and Chief Scientific Officer of the Allen Institute for Brain Science, a private research institution in Seattle. He was a professor of biology and engineering at the California Institute of Technology for 27 years. He continues to study the neural basis of consciousness.
- ALEXANDER SZALAY, PhD – is the Bloomberg Distinguished Professor in the Department of Physics and Astronomy and Department of Computer Science and Director of the Institute for Data Intensive Science at Johns Hopkins University. He is the architect for the Science Archive of the Sloan Digital Sky Survey, the world’s largest astronomical survey.
- JOSHUA VOGELSTEIN, PhD – is Assistant Professor of Biomedical Engineering at Johns Hopkins University, where he is a member of the Kavli Neuroscience Discovery Institute. Vogelstein created and manages Neurodata, an open data hub for the neuroscience community.
The following is an edited transcript of their roundtable discussion. The participants have been provided the opportunity to amend or edit their remarks.
THE KAVLI FOUNDATION: Alex, neuroscience seems to be at the brink of sharing the massive amount of new data being gathered about the brain. How did the shift toward open data transform the field of astronomy?

ALEXANDER SZALAY: Data sharing has fundamentally changed how we do science. In fact, some of the steps in the scientific process have reversed. It used to be that scientists collected data, then analyzed and published what they had gathered. Today, there are large groups of scientists who collect data and effectively publish it, and that’s when the analysis begins. This is exemplified by big collaborations like the Sloan Digital Sky Survey in astronomy and also in other fields, such as the Human Genome Project in the field of genetics and the Large Hadron Collider, the world’s most powerful particle accelerator, in physics.
The other fundamental change we see is that data collection is becoming a separate process from analysis. There are hundreds if not thousands of people working on some of these projects because the data are publicly available and the analysis can be done by any individual with a smart idea.
CHRISTOF KOCH: Alex, someone like Galileo built his own instrument, collected his own data, did his own analysis and then published—in his case in a book. That process of doing science has remained intact through the centuries. Are you saying that different specialists now carry out each part—that some scientists just build instruments, others just collect the data and a third set of people just analyze it?
SZALAY: Well, usually the collaborations that build the instruments also collect the data. You don’t get hundreds of millions of dollars to build the Large Hadron Collider unless you specify some of the key projects you want to do with it. What I’m saying is that the science doesn’t stop there. After that the research community really dives in to study the data.
KOCH: Alex, what fraction of today’s astronomy papers are based on data sets collected by groups such as the Sloan Digital Sky Survey?
SZALAY: Probably 30 percent.
KOCH: Wow.
TKF: Has there also be a cultural change in astronomy as the result of Sloan?
SZALAY: Twenty years ago, hardly any astronomy data were made public. Astronomers guarded their data like gold. So, yes, somehow the sociology has completely changed.
JOSHUA VOGELSTEIN: I think it’s important to note that you and the other scientists at the Sloan Digital Sky Survey made a commitment to your funders to release data on a regular basis. You’re not doing it out of the goodness of your heart.
SZALAY: That’s true. But most of the people who built Sloan were at the same point in their career as I was. We were established—it didn’t matter much whether we published three more papers per year on astronomy—and we wanted to create a legacy, to build something that would change astronomy. I think we actually pulled it off. [Laughter] We changed the culture of astronomy as well as the way astronomy is done today.
TKF: Christof, you lead the Allen Institute for Brain Science in Seattle, which has been a pioneer in promoting open data in neuroscience. What is the Allen’s motivation?

KOCH: Thirteen years ago, our founder Paul Allen wanted to make a difference by doing something that couldn’t be done at universities. At that time, data sharing in neuroscience was even less common than it is today. Nobody in neuroscience publicly released their data. So we decided to create the Allen Brain Atlas, a survey of the 20,000 genes expressed in the mouse brain, and to release the data to our internal scientists and to everybody else three times a year. In fact, it was partly inspired by the Sloan Digital Sky Survey.
TKF: Why do you think neuroscience lags behind astronomy in data sharing?
KOCH: One thing that distinguishes neuroscience and astronomy is the cost of doing science. In astronomy, I think there is a culture of data sharing because telescopes cost hundreds of millions of dollars, which forces researchers to work together. In neuroscience, a much less mature science, instruments cost a half a million or a million dollars. So there’s less incentive to collaborate and share the data that result.
Also, there’s still very much an ethos in neuroscience that a single graduate student has to build his or her own instrument, train the animals, acquire the data, write a data analysis program and publish. Only slowly are we realizing that we just can’t do this anymore because it leads to irreproducible data, to the well-known replication crisis. For example, it is estimated that two out of three experiments in the biomedical sciences cannot be reproduced. This is partly because of the vast complexity of the biological systems we’re studying. So we need to move toward standardizing the way we do experiments and releasing data so that they can be readily compared to other experiments.
“[The Sloan Digital Sky Survey] changed the culture of astronomy as well as the way astronomy is done today.”—Alex Szalay
TKF: Alex, was reproducibility a problem in astronomy before scientists began working with open data?
SZALAY: Very much so. With Sloan, we keep the raw data that come off the telescope, archive them and make them available to everyone. So people don’t have to believe the results of our data processing. They can redo it on their own.
TKF: Joshua, you are a vocal advocate of open science. What converted you?

VOGELSTEIN: During my PhD, I made my code open source and noticed that lots of people really appreciated that. That was nine years ago. Since then, I’ve gotten about one email per week from someone I’ve never met asking me how to run the code, which demonstrates to me that it is useful to the community. That also led to more citations of my work. So making my code open was all good.
My research revolves around understanding the statistics of networks in the brain. More recently, Clay Reid, a neuroscientist from Harvard who is now at the Allen Institute for Brain Science, had a data set that I wanted to explore. He gave me the data and I wrote code to do that. Once I did, it was easy again to let everyone else in the world use it. So that’s how the NeuroData open-data project got started. Now, we’re building and deploying tools that anyone can use to analyze various kinds of neuroscience data.
As Christof will tell you, collecting the data for big reference data sets such as the Allen Brain Atlas still costs millions of dollars and generates so much data that one lab could not fully process them. It just makes sense that it would be a community effort to study large data sets.
“Collecting the data for big reference data sets still costs millions of dollars and generates so much data that one lab could not fully process them. It just makes sense that it would be a community effort to study large data sets.”—Joshua Vogelstein
TKF: Alex, you’ve said that a new scientific revolution is taking place that you call the “fourth paradigm.” What do you mean by that?
SZALAY: What is happening now, the fourth paradigm of science, is the emergence of data-intensive science, in which a lot of primary discoveries are based upon the data. It pulls together everything that came before. The first paradigm was when we were simply collecting data about the natural world in a very empirical fashion. Think of the star charts made by Galileo and the Danish astronomer Tycho Brahe in the 1500s. Then, Brahe handed the data to Johannes Kepler, who abstracted it into equations that described the motion of the planets. Kepler captured all those data with simple equations. That was the second paradigm, the theoretical paradigm. Then, roughly during World War II, we started to use computers to solve complex problems, which represents a third, computational paradigm.
TKF: The fourth paradigm you just described is affecting every field of science, including neuroscience. So is it inevitable that neuroscience will change to become more open?

SZALAY: Yes.
KOCH: Yes, in time, except we haven’t even reached the point of Galileo or Kepler because the objects we investigate, multi-cellular organisms, are so complex. Aside from a few basic equations describing the dynamics of the membrane potential in individual neurons, which we understand very well, we don’t have anything equivalent to classical physics in neuroscience.
TKF: Let’s talk about that a little more. What are the ways that dealing with big data in neuroscience differs from astronomy or physics?
KOCH: The biggest difference is, when we’re talking about astronomy, we’re talking about one sky, one universe. In biology, are you talking about the mouse? The young mouse or the old mouse? The sick mouse? And which strain of mice? And then, there are different parts of the brain; the visual cortex is nothing like the hypothalamus. So the complexity of the brain is much greater because we’re dealing with an evolved system, created from billions of organisms over billions of years by the process of natural selection. Yet, we’re looking for simple ways to understand this vast, complex system, to understand how the mind arises out of the brain.
VOGELSTEIN: I largely agree, but I’m going to nitpick a little. In science, things appear to be really complicated when we don’t have general principles that make things that seem unrelated actually very related. Neuroscience is in that state. So my perspective is that it’s a bit premature to say neuroscience is more complicated. The brain clearly seems more complicated, but maybe we’re just lacking the insights that will enable us to link things together.
KOCH: I take your point. Maybe because I’ve been around 30 years longer than you, Joshua, I’m somewhat more skeptical. You might be right.
TKF: I read that a whopping 40 percent of professional astronomers use software developed by Alex and his team at Johns Hopkins for the Sloan Digital Sky Survey. Will it be possible to achieve something similar in neuroscience—specifically, a suite of software tools that can serve almost everyone?
KOCH: Well, in neuroscience, we’re talking about a very diverse community. There is a large number of cognitive scientists and clinicians who do whole brain imaging in humans. Then there are cellular-focused neuroscientists like Joshua and me who are looking primarily at cells, mainly in animals. Those are radically different scales and organisms. So there are more diverse sub-communities than in astronomy.
VOGELSTEIN: I agree with that. I would add that one of the brilliant insights Alex and his colleagues had when they created the software that supports the Sloan Digital Sky Survey is that they let the community determine what questions they wanted to ask about the data, rather than predetermining them. That was really transformative. And so, it will be really important as we develop tools to investigate the brain that they are general enough to enable any neuroscientists to ask questions that are of interest to them. Alex, do you agree?
SZALAY: Absolutely. That insight came from a letter to the editor in Nature or Science in which the author argued that most data systems in science are created in a way that limits the creativity of scientists. He also argued that you should allow a back door into the data that enables people to ask any questions they want. So we created it and people said that we were insane, that nobody in astronomy would want to learn our programming language and that we would get saturated with badly formulated queries. Remarkably, neither of those happened. Astronomers are using this tool not like a hammer but rather like a violin. They play exquisite music with it.
“[I]t is estimated that two out of three experiments in the biomedical sciences cannot be reproduced. This is partly because of the vast complexity of the biological systems we’re studying. So we need to move toward standardizing the way we do experiments and releasing data so that they can be readily compared to other experiments.”—Christof Koch
TKF: Alex, you lead the SciServer Project to create online tools that enable data-driven science. These tools are inspired by those you developed for the Sloan Digital Sky Server but aimed at scientists working in other fields. How is SciServer designed to accelerate discovery outside of astronomy?
SZALAY: We have been able to reuse and re-engineer the components we developed for astronomy and adapt them for a range of disciplines, from genomics to material science and from fluid mechanics to environmental science. And we are working our way toward using some of these tools for neuroscience.
What these fields have in common are very large data collections. What they lack is infrastructure—effective tools for accessing and analyzing large data collections. So that’s where SciServer comes in. Our tools make big data accessible, usable and useful.
TKF: Christof, over the summer, the Allen Institute launched the Allen Brain Observatory, a survey of the activity of more than 30,000 individuals neurons in the visual system of the mouse. What prompted you to create such a tool for the neuroscience community?
KOCH: Everything we know about the brain—behavior and perception and, my particular interest, consciousness—derives from the activity of very large numbers of neurons and associated glial cells. Yet, over the past 50 years, most neuroscientists have only surveyed a handful of neurons at a time. So we thought that if we surveyed the behavior of a large number of neurons, in this case in the visual cortex, we can better understand the rules that govern how these cells communicate and process information. By releasing the data to the public, people like Josh can come in, analyze the data and test their theories about how the brain works in a systematic way. We released the raw data as well as tools that help researchers access and explore them.
TKF: Joshua, you are already using some of those data that were just released. Do you feel like a kid in a candy shop?
VOGELSTEIN: I’ll be feeling like a kid in a candy shop soon. The Allen Institute initially released about 30 terabytes of data, but the tools to do the analysis on that data are still in a fledgling state. I can look at the data but not really in the ways that I want to. So I’ve been trying to get the data into a format that makes it easy to look at. Scientists take that for granted. But as soon as the data are made of more bits than fit onto your computer monitor at one time, you need new ways to look at it.
TKF: In addition to the types of projects Alex and Christof just described, what else needs to happen to promote data sharing among neuroscientists and make it a success?
VOGELSTEIN: One thing that both Christof and Alex know very well, but is perhaps not as well appreciated by the community, is how crucial it is to collect reference data, whether it’s about the human or mouse brain or the sky. Astronomers, geneticists and particle physicists transformed their disciplines by making reference data sets available along with tools to do the analyses on them. None of them proceeded by letting lots of different people open their own data. I’m not saying that won’t be a useful way forward but the historical evidence is that generating really beautiful, carefully curated reference data sets has an impact. I think neuroscience can learn from that.
TKF: The Allen Institute is doing that, but it is just one private institution. Are there other promising examples?
VOGELSTEIN: The Howard Hughes Medical Institute has a really wonderful open-science policy. IARPA [Intelligence Advanced Research Projects Activity], which has a program that seeks to reverse-engineering the algorithms of the brain, is requiring a massive open data-collection effort. In all these cases, it’s the funders that are making open data a priority, just as the National Science Foundation did for cosmology. The National Institutes of Health (NIH) seems willing to follow suit.
KOCH: We’ll see how far the NIH will go. As we all know, putting data online isn’t as easy as saying, “Here’s an Excel sheet.” You have to annotate it, curate it and be ready to answer questions about it. So it takes real resources. If there isn’t specific money allocated to support it, people would rather spend their time doing experiments.
VOGELSTEIN: Let’s not forget that you don’t have to make data open-access just because you’re a good-natured human being. There are real incentives to do so that count in today’s publish or perish world. If you publish data that’s really useful, lots of people will cite it. As Alex pointed out, the Sloan Digital Sky Survey has been cited more than 200,000 times! There are examples from neuroscience, too, such as the Human Connectome Project, which is creating a wiring diagram of the human brain and releases those data publicly.
TKF: The Sloan Digital Sky Survey also made astronomy a truly global science. Today, the collaboration includes 51 member institutions and a thousand scientists from around the world. Joshua, you have recently been involved in discussions about establishing a global brain initiative. What impact could data sharing have internationally?
VOGELSTEIN: There are thousands, even tens of thousands, of scientists out there who would love to be working on neuroscience, but the research costs are too high. Making data available really opens the door to democratizing science by lowering the barriers to entry. You no longer need access to millions of dollars to do the best neuroscience research in the world. You just need Internet access and a really great idea.
“Making data available really opens the door to democratizing science by lowering the barriers to entry. You no longer need access to millions of dollars to do the best neuroscience research in the world. You just need Internet access and a really great idea.”—Joshua Vogelstein
TKF: Joshua, you also planned a meeting this year that led to the idea of “The International Brain Station” that could help break down barriers to data sharing in neuroscience. Can you describe the vision and what it could achieve?
VOGELSTEIN: The kernel of the idea is based on a view of the scientific process as an “upward spiral”: a collective effort where each new experiment yields data, upon which analysis is performed, leading to new or refined models, which suggest novel experiments. The goal of the The International Brain Station (TIBS) is to build technology that would democratize brain science, so that all brain scientists—professional and otherwise—can build on the shoulders of one another. To make that a reality, TIBS would enable “cloud neuroscience,” meaning that the data, the code and the analytic results from neuroscience experiments all live in the cloud together, where it could be accessed by anyone.
TKF: Alex, what lessons can neuroscientists learn from astronomy about how to shift data-sharing into high gear?
SZALAY: One of the lessons we learned is that nothing has to “go to eleven,” as in the movie Spinal Tap. You just have to create something that is good enough, say “up to nine.” So when you process data on such a large scale, the data don’t have to be absolutely perfect. Neuroscientists have to find the trade-off between perfection and the time and cost associated with making the data available. What is most important is to process the data in a very consistent, standardized way, and earn the TRUST of the community in the process.
—Lindsay Borthwick, Fall 2016
Related Posts